- University of Texas at Austin
- Ph.D. Candidate in Department of Physics
- Center for Theoretical and Computational Neuroscience
- Contact Information
- luyan.yu [at] utexas.edu
- NHB 4.362, 100 E 24TH ST
- Austin, Texas 78712, USA

The idea of quantum Boltzmann machine is straight-forward: simply replace the hidden and visible layers with the quantum Pauli spins. But doing so will make the problem computationally intractable on a classical computer due to the exponentially large state space. Unless we have a real quantum computer, we will not be able to train the Boltzmann machine.
Instead, if we only quantize the hidden unit layer and keep the visible layer classical, we avoid intractable computations and meanwhile ‘steal’ some benefits from the quantum world. One such benefit we observe is that it can somehow avoid local minima during the searching of state space if we apply the quantum restricted Boltzmann machine to reinforcement learning tasks.
Restricted Boltzmann machine
A restricted Boltzmann machine (RBM) 1 .is a bipartite graph endowed with a Markov random field (basically means a set of random variables). Each RBM has
- a layer of $n$ hidden vertices with values $h_i\in \{-1,1\}$ and weights $c_i$, and
- a layer of $m$ visible vertices with values $v_j\in \{-1,1\}$ and weights $b_j$.
‘Restricted’ means there is no connection within each layer while there are full connection between the two layers, weighted by connectivity matrix $w_{ij}$.

Given the value of all hidden and visible vertices $(\bm{v},\bm{h})$, called a configuration, we associate a real value to it by $$ E_{\text{RBM}}(\bm{v},\bm{h}) = - \sum_{j=1}^m \sum_{i=1}^n w_{ij} h_i v_j - \sum_{j=1}^m b_j v_j - \sum_{i=1}^n c_i h_i $$ $E_\text{RBM}(\bm{v},\bm{h})$ is called the energy function of RBM. Then we can define the probability for such configuration to occur by the boltzmann weighting $$ p(\bm{v},\bm{h})=\frac{1}{Z}e^{-E(\bm{v},\bm{h})}, $$ where $Z=\sum_{\bm{v},\bm{h}} e^{-E(\bm{v},\bm{h})}$ is the partition function. Moreover, the conditional probability function of each layer can be defined as $$ p(\bm{v} | \bm{h})=\frac{1}{Z(\bm{v})}\sum_{\bm{h}}e^{-E(\bm{v},\bm{h})}, \,\, p(\bm{h} | \bm{v})=\frac{1}{Z(\bm{h})}\sum_{\bm{v}}e^{-E(\bm{v},\bm{h})}, $$ where $Z(\bm{v})=\sum_{\bm{h}} e^{-E(\bm{v},\bm{h})}$, $Z(\bm{h})=\sum_{\bm{v}} e^{-E(\bm{v},\bm{h})}$ are partition functions of each layer.
Quantum restricted Boltzmann machine
A (clamped) quantum restricted Boltzmann machine (qRBM) is constructed by simply replacing the hidden layer with Pauli spin matrices.

Now the energy function becomes A Hamiltonian $$ H_{\text{qRBM}}(\bm{v}) = - \sum_{v,h} w_{vh} v \sigma_h^z - \sum_{h} c_h \sigma_h^z - \sum_{h} \Gamma_h \sigma_h^x. $$ Note that in the above equation, an extra term with $\sigma_x$ Pauli matrices is introduced to make the Hamiltonian non-trivial. And the probabilities can be defined similarly using the notations from quantum mechanics.
Reinforcement learning in a nutshell
In the context of reinforcement learning, we have an agent who can act differently according to the current state within some environment. The agent will get reward according to the action it chooses under some state. The goal of reinforcement learning is to find a policy to maximize agent’s long-term reward. One of the most well-know algorithm in reinforcement learning is the Q-learning algorithm.
Settings
Mathematically, an action in the action set $\mathcal{A}$ is a map which maps within the set of states $\mathcal{S}$, i.e., $a\in \mathcal{A}, a:\mathcal{S}\rightarrow \mathcal{S}$. In a more general situation, the state of agent $s$ becomes $a(s)$ with probability $p(s’\mid s,a)$ after perform action $a$. For simplicity, we only consider the case where $p(a(s)\mid s,a)=1$, i.e., the transition of states is definite. Moreover, we can define the reward function $r(s,a)$ representing the immediate reward after performing action $a$ in state $s$. Reward is not necessarily a positive number. For example, we can use positive value for reward and negative number for penalty.
Our goal is to find a policy, which is a map $\pi:\mathcal{S}\rightarrow \mathcal{A}$, that maximizes the long term reward. Given policy $\pi$ and initial state $s_0$, we can generate a chain of actions and states accordingly $$ s_0 \xrightarrow{\pi} a_0 \xrightarrow{} s_1 \xrightarrow{\pi} a_1 \xrightarrow{} s_2 \xrightarrow{\pi} \cdots \xrightarrow{} s_t \xrightarrow{\pi} a_t \xrightarrow{} \cdots $$ With this state-action chain, we can then define the long term reward as a function of initial state under certain policy $\pi$ as $$ \langle R(s) \rangle_\pi = \left\langle \sum_{k=0}^{\infty} \gamma^k r_{k} \mid s_0=s \right\rangle_\pi $$ where $r_k = r(s_k,a_k)$ is the reward from $k^{\text{th}}$ step and $\gamma\in[0,1)$ is a discount factor to ensure the convergence of the series.
Q-learning
To solve this problem, Q-learning algorithm takes a step further. For given policy, it defines so-called Q-function $$ Q^\pi(s,a) = \left\langle \sum_{k=0}^{\infty} \gamma^k r_{k} \mid s_0=s, a_0= a \right\rangle_\pi $$ If we can find a point-wise optimal Q-function varying policy $\pi$: $Q^\ast=\max_\pi Q^\pi$, we will be able to give the optimal policy $\pi^\ast(s)=\text{argmax}_a Q^\ast(s,a)$. The existence of such optimal Q-function can be proved using fixed point theorem within an appropriately defined Banach space. Suppose we have found the optimal Q-function. It satisfies $$ \begin{align} Q^\ast(s,a) &= \left\langle r_0+\gamma \sum_{k=0}^{\infty} \gamma^k r_{k+1} \mid s_0=s, a_0= a \right\rangle \\ &= r(s,a)+\gamma \max_{a’} Q^\ast(a(s),a’). \end{align} $$ There is one equation for each pair of $(s,a)$, so overall we have $|\mathcal{S}|\times|\mathcal{A}|$ equations which can be solved iteratively $$ Q_{n+1}(s,a) = r(s,a)+\gamma \max_{a’}Q_n(a(s),a’). $$
Function approximation with qRBM
However, this method will take huge computational resources if the state or action space becomes large. Alternatively, we may want to choose some a priori function $Q(s,a;\bm{\theta})$ which is differentiable with respect to a reasonable number of parameters $\bm{\theta}$. We expect to find good solutions by minimizing the square of temporal difference $$ E_\text{TD}= r(s,a)+\gamma \max_{a’}Q_n(a(s),a’) - Q_{n+1}(s,a) $$ The update rule of $\bm{\theta}$ is given by gradient descent $$ \Delta \bm{\theta}=-\nabla E_\text{TD}^2 \approx \lambda E_{\text{TD}} \nabla_{\bm{\theta}} Q(s,a;\bm{\theta}) $$ where $\lambda$ is the learning rate.
Q-learning with RBM
The choice of such function approximator is where Boltzmann machine comes into play. The following procedure of using RBM as function approximator was proposed by Sallans
2
. If we arrange the elements in state set in a particular order $\{s_i\}_{i=1\cdots |\mathcal{S}|}$, then each element can be encoded into
$$
\bm{s}_i
=(\underbrace{-1,\cdots,-1}_{i-1 \text{times}},1,
\underbrace{-1,\cdots,-1}_{|\mathcal{S}|-i \text{times}}),
$$
where we use bold letter $\bm{s}$ for the vector corresponding to state $s$ hereafter. We can carry on similar procedure for the action set. With such encoding, each state-action pair is a vector of the following form
$$
(\bm{s},\bm{a})
=(\underbrace{-1,\cdots,-1,1,-1,\cdots,-1}_{\bm{s}},
\underbrace{-1,\cdots,-1,1,-1,\cdots,-1}_{\bm{a}}).
$$
We can then construct an RBM with its visible layer being such state-action pair, i.e., $\bm{v}= (\bm{s},\bm{a})$

The form of Q-function is chosen to be the negative free energy of the RBM $$ Q(s,a)=-F(\bm{s},\bm{a}) = -\ln Z(\bm{s},\bm{a}) $$ As we know, a system in equilibrium has a minimized free energy. Since the process of maximizing Q-function is equivalent to the process of minimizing free energy, we expect our optimal Q-function to occur when the constructed RMB is in equilibrium.
Replace the RBM with qRBM
Now we want to make use of our quantum RBM. Thanks to quantum mechanics, we can also define the free energy in this setting $$ F(\bm{s},\bm{a}) = \text{Tr}\left[ \rho(\bm{s},\bm{a}) H(\bm{s},\bm{a}) \right] $$ where $\rho(\bm{s},\bm{a})$ is the density matrix of the qRBM defined as $$ \rho(\bm{s},\bm{a}) = \frac{1}{Z(\bm{s},\bm{a})} e^{-H(\bm{s},\bm{a})} $$
Experiments
We demonstrate the power of qRBM using the Grid World problem. The following is a simple example of grid world. The green block is the reward and red block is penalty. Brown block is prohibited area.
Solve the grid world problem using Q-learning with qRBM

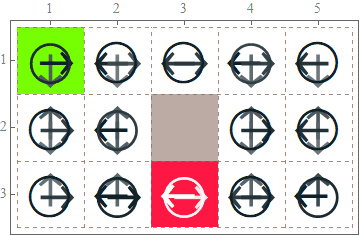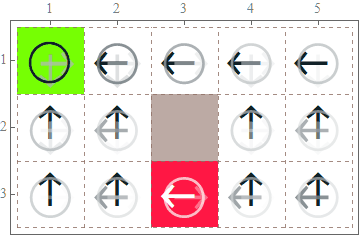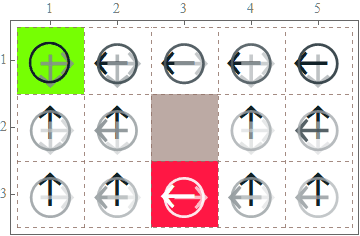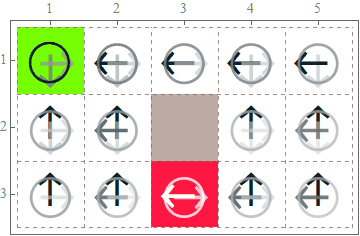
Our findings
We find that it is possible to avoid local minima during the learning process with qRBM. This is believed to be a quantum effect. In the following plots, the red learning curve is using the RBM and the blue one is using the qRBM. We can clearly see that the classical RBM falls into a local minimum for a period of time while the qRBM doesn’t.
